旧的生命周期
constructor构造函数
构造函数的主要作用就是1、通过this.state来初始化内部的state。2、为事件函数绑定this。在组件挂载之前,会调用它的构造函数。
我们知道如果在为 React.Component 子类实现构造函数时,应在其他语句之前前调用 super(props)。否则,this.props 在构造函数中可能会出现未定义的 bug。我们可以来想想为什么每次都必须要写super,我们可以不写它么?
首先,super指的是父类的构造函数。在调用super之前,我们是不能使用this的。为什么这样做呢,我们试想一下,如果在调用super之前不禁止this,我们来看看下面这个例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Father {
constructor(name) {
this.name = name
}
}
class Son extends Father {
constructor(name) {
this.greet();
super(name)
}
greet() {
console.log('hello my name is' + this.name);
}
}
我们可以看出在这个例子中,this.greet()在super()给this.name赋值之前就已经执行了。这时候this.name尚未定义。为了避免这种情况,强制在使用this之前先行调用super。
下面我们看看为什么要传入props么?
我们可以看看React内部1
2
3
4
5
6class Component {
constructor(props) {
this.props = props;
// ...
}
}
在React内部,的构造方法里我们一目了然,它直接将props赋值给this.props。
即便你调用super()的时候没有传入props,你依然能够在render函数或其他地方访问到this.props。这是因为,React 在调用构造函数后也立即将 props 赋值到了实例上1
2
3 // React 内部
const instance = new YourComponent(props);
instance.props = props;
尽管这样,我们也要避免使用super()而使用super(props),因为如果使用super(),会使得 this.props 在 super 调用一直到构造函数结束期间值为 undefined。
【注意】避免将props的值直接赋值给state。因为这样做毫无意义,并且props改变的时候,state并不改变。
componentWillMount
这是一个即将被废弃的方法。而且16.3已经将这个更名为UNSAFE_componentWillMount。它在挂载组件前调用,在componentWillMount中执行setState是毫无意义的。因为组件只挂在一次,componentWillMount也只执行一次,应该把这里的setState放到constructor中。
之前讨论的最多的就是异步请求api的时候,应该在componentWillMount里还是componentDidMount中,网上有一种说法是,放在componentWillMount中异步的请求数据,先会render一次空数据,等数据回来之后再走一遍render,所以应该放到componentDidMount中,但我觉得这种说法是不可靠的。因为在DidMount之前,同样也会render一遍空数据。早发起请求确实能早点获得结果,但是省的这几微妙根本微不足道。再加之WillMount即将被废弃。所以应该避免使用它。还有一点要注意,它是服务器渲染上调用的唯一方法。
render
render()是在componentWillMount()和componentWillReceive()之后调用。主要的作用是渲染组件,它是在class组件中唯一必须实现的方法。render应该为纯函数,意味着在state不变的情况下。每次调用返回的结果都应该相同。
componentDidMount
该方法会在render方法后立即执行,它跟componentWillMount一样也是永远只执行一次。在这里可以对DOM进行操作,因为这时组件已经加载完毕。之前我们也说了,网络请求数据的操作也应该放在这里。需要注意的是render函数结束之后,不会立即调用componentDidMount。是因为render函数本身并不往DOM树上渲染或者装载内容,它只是返回一个JSX表示的对象,然后由React库来根据返回对象决定如何渲染。而React库需要把所有组件返回的结果综合起来。才知道该如何产生对应的DOM修改。只有React库调用了全部render后,再依次调用各个组件的componentDidMount函数作为装载过程的收尾。1
2
3
4
5
6
7
8
9componentWillMount First
render First
componentWillMount Second
render Second
componentWillMount Third
render Third
componentDidMount First
componentDidMount Second
componentDidMount Third
componentWillReceiveProps
这个的用法主要是,需要根据新的prop改变状态,可以比较this.props和nextProps,并使用setState()执行state转换。
一般对这个方法有一个误区,就是它会通常被认为当props改变了它才会被调用,但事实是,只要是父组件的render函数被调用,在render函数里面被渲染的子组件就会经历更新过程,不管父组件传给子组件的props有没有改变,都会触发子组件的componentWillReceiveProps。我们唯一能保证的就是当props改变的时候,一定会触发componentWillReceiveProps,反之不然。注意在setState触发的更新过程是不会调用这个方法的。我们在使用的时候需要避免,在这个方法中调用父组件的回调函数修改父组件的state,这样父组件rerender会导致死循环。
同样这个方法在React 17中将被废弃。
想要使用应该写成UNSAFE_componentWillReceiveProps
shouldComponentUpdate
根据shouldComponentUpdate的返回值,判断React组件的输出是否受当前state或props更改的影响。意思就是判断组件是否重新渲染。默认行为state每次发生改变的时候组件都会重新渲染。我们要注意在首次渲染或使用forceUpdate()时不会调用该方法。在官方介绍中,说应该考虑使用PureComponent组件,而不是手动编写shouldComponentUpdate()。PureComponent会对props和state进行浅层比较。【注意】 返回 false 并不会阻止子组件在 state 更改时重新渲染。
componentWillUpdate
这个方法很简单,就是当组件收到新的props或state时,会在渲染之前调用这个方法。初始渲染不会调用它。
同样这个方法在React 17中将被废弃。
想要使用应该写成UNSAFE_componentWillUpdate
componentDidUpdate
componentDidUpdate会在更新后会被立即调用。首次渲染不会执行此方法。也可以在这个函数中直接调用setState(),但它必须包裹在一个条件语句中。要不然就会导致死循环。也不要将props镜像给state,应该直接使用props。
componentWillUnmount
componentWillUnmount() 会在组件卸载及销毁之前直接调用。在此方法中执行必要的清理操作,例如,清除 timer,取消网络请求或清除在 componentDidMount() 中创建的订阅等。
componentWillUnmount() 中不应调用 setState(),因为该组件将永远不会重新渲染。
新的生命周期
新增了两个生命周期getDerivedStateFromProps和getSnapshotBeforeUpdate
我们先来看看图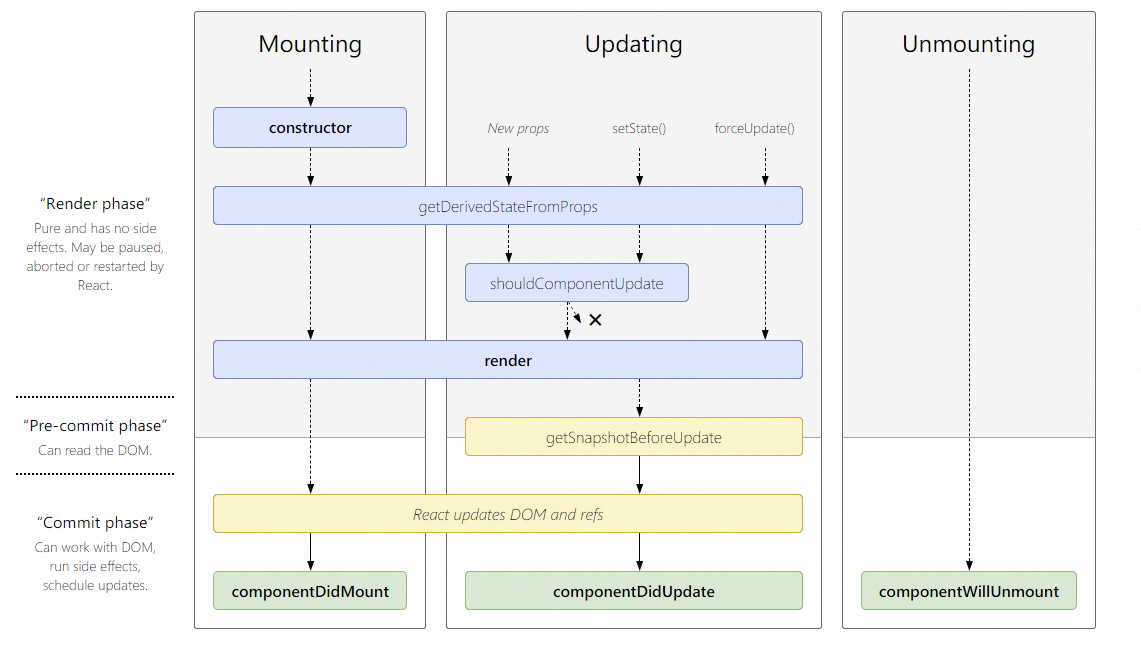
getDerivedStateFromProps
组件每次被rerender的时候,都会触发这个生命周期函数,无论是props更新,还是setState,还是调用forceUpdate(),并且它在组件挂载和后续更新时都会被调用。它应该返回一个对象来更新state,如果返回null则不更新任何内容。注意,getDerivedStateFromProps是一个静态函数,所以函数体内不能访问this,输出完全由输入决定。
getSnapshotBeforeUpdate
它的触发时间实在update发生的时候,render之后,组件dom渲染之前。这个函数的返回值会作为componentDidUpdate的第三个参数。它可以来替代componentWillUpdate。
还有两个生命周期函数
getDerivedStateFromError
这个生命周期函数会在子组件抛出一个错误之后被调用。它会接收到这个throw出来的参数,然后去return一个值去更新state来处理这个错误。设置错误边界可以让代码在出错的情况下,也能将错误显示到页面中,而不是出现空白页面。
一般使用static getDerivedStateFromError() 来渲染一个提示错误的UI,使用componentDidCatch() 来记录一些error的详细信息,错误调用栈等等
componentDidCatch
这个也是在后代组件抛出错误后被调用。 它应该用于记录错误之类的情况。如果要是降级渲染UI,还是应该用getDerivedStateFromError来处理。
父子组件生命周期执行顺序总结
当子组件自身状态改变时,不会对父组件产生副作用的情况下,父组件不会更新,不会触发父组件的生命周期。
当父组件中状态发生变化(包括子组件的挂载以及)时,会触发自身对应的生命周期以及子组件的更新。
还是洋葱圈模型,render 以及 render 之前的生命周期,则 父组件 先执行。render 以及 render 之后的声明周期,则子组件先执行,并且是与父组件交替执行。


