React Fiber现在应该是一个应知必会的内容了。
什么是Fiber呢?
官方的话说“React Fiber是对核心算法的一次重新实现。”
首先我们要理解重新实现,就得知道之前有什么问题,我们知道之前React的更新是同步的。React在加载或者更新组件的时候,会进行一系列的操作如调用生命周期,计算和对比Virtual DOM,最后更新DOM这整个过程都是同步的。在这个过程中主线程只负责更新操作,无法做任何事情,这就会导致页面的卡顿。
React Fiber的特点
通过分片的方式来破解同步时间过长。他的特点:
- 增量渲染(把渲染任务拆分成块,匀到多帧)
- 更新时能够暂停,终止,复用渲染任务
- 给不同类型的更新赋予优先级。
- 并发方面新的基础能力。
Fiber Tree
维护每一个分片需要一个数据结构。就是Fiber树,长下面这个样子。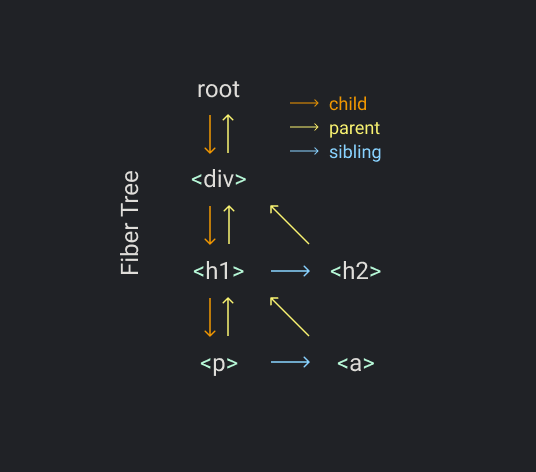
可以看出来这就是一个链表树。
在render的过程中,我们创建root fiber并设为nextUnitOfWork放在performUnitOfWork中进行,在里面我们要做三件事。
- 将元素加到DOM上
- 创建该元素的子fiber元素。
- 选择下一个工作单元
这个fiber树的目标之一就是更方便的找到下一个工作单元。我们可以看到每一个fiber都廉洁着它的子元素,兄弟元素和父元素。
我们来看一下它的顺序。
当我们完成一个fiber的渲染工作。如果有子孩子,子孩子将会成为下一个工作单元。如果没有子孩子,它的兄弟孩子将会成为下一个工作单元。如果既没有子也没有兄弟,它的叔叔节点将会成为下一个工作单元(也就是父节点的兄弟节点)。直到回到root节点,整个render过程结束。
我们来用代码实现一下
1 | function createDom(fiber) { |
在render函数中我们设置root为nextUnitOfWork,之后浏览器准备好了之后,将会调用我们的workLoop
我们来实现performUnitOfWork函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44function performUnitOfWork(fiber) {
if (!fiber.dom) {
fiber.dom = createDom(fiber)
}
if (fiber.parent) {
fiber.parent.dom.appendChild(fiber.dom)
}
const elements = fiber.props.children
let index = 0;
let prevSibling = null;
while (index < elements.length) {
const element = elements[index];
const newFiber = {
type: element.type,
props: element.props,
parent: fiber,
dom: null,
}
if (index === 0) {
fiber.child = newFiber
} else {
prevSibling.sibling = newFiber
}
prevSibling = newFiber
index++
}
if (fiber.child) {
return fiber.child
}
let nextFiber = fiber
while (nextFiber) {
if (nextFiber.sibling) {
return nextFiber.sibling
}
nextFiber = nextFiber.parent
}
}
遍历每一个child创建新的fiber。然后再为他添加孩子或者兄弟节点,是否为兄弟取决于是否是第一个孩子。最后我们搜索下一个工作单元,先尝试是否有孩子节点,然后再试兄弟,最后是叔叔这样的顺序。
这就是整个performUnitOfWork的过程。